Sound personalization is quickly becoming a standard feature across consumer audio. From earbuds to TVs, brands increasingly promise tailored listening experiences taking into account individual hearing ability.
But there’s a fundamental issue: most of today’s personalization solutions rely on linear, frequency-based gain adjustments similar to traditional equalization (EQ). While EQ can adjust tonal balance, it does not address how humans actually perceive sound in the presence of hearing loss. For product teams aiming to deliver meaningful differentiation, this distinction matters more than ever.
In contrast, Mimi Sound Personalization is built on established non-linear processing principles rooted in auditory science. Its biologically-inspired architecture is designed to replicate healthy cochlear behavior, enabling level-dependent compensation that more accurately reflects how sound is perceived by listeners with impaired hearing.
This distinction highlights a broader shift in the industry: from static sound tuning to hearing-aware signal processing.
Hearing is not linear and neither is hearing loss
Human hearing is inherently non-linear.
In a healthy auditory system, the cochlea applies level-dependent amplification:
- Soft sounds are amplified to remain audible
- Loud sounds are naturally compressed to remain comfortable
This mechanism allows us to perceive a wide range of sound intensities without distortion, discomfort, or risk of damage.
However, in cochlear hearing loss, this natural compression is reduced or lost:
- Soft sounds become inaudible
- Loud sounds remain relatively unchanged, or may even appear too loud
The result is a compressed perceptual dynamic range and a distorted relationship between sound intensity and perceived loudness.
This phenomenon, known as loudness recruitment, is not a simple volume issue. It is a complex structural change in perception.
This change in perception can be visualised as follows:
![[lightbox]](https://cdn.prod.website-files.com/6818bfbe7d79e080f9ab7199/69e621caa550005b0aac0383_loudness-perception-hearing-loss-vs-normal-hearing.png)
Why EQ-based personalization falls short
Conventional equalization (EQ) is a linear processing method that modifies signal level dependent on input frequency, but regardless of input level.
Personal sound solutions relying on such static gain adjustments have a fundamental limitation, that because an EQ acts independent of signal intensity, applying the same adjustment to both soft and loud sounds, it cannot account for loudness recruitment.
This creates an unavoidable trade-off:
- Increase gain → soft sounds become audible, but loud sounds become uncomfortable
- Reduce gain → comfort is preserved, but important details disappear
In real-world listening, where speech and media span wide dynamic ranges, this leads to:
- Reduced speech clarity at low levels
- Listening fatigue at higher levels
- Frequent manual volume adjustments
In short, this approach ignores principal effects of hearing loss on auditory perception.
![[lightbox]](https://cdn.prod.website-files.com/6818bfbe7d79e080f9ab7199/69e622101d0cd10cc2f73a18_linear-eq-vs-hearing-loss-compensation.png)
Real-world audio requires dynamic solutions
The shortcomings of EQ may not be obvious in controlled demos or highly compressed listening scenarios where the acoustic dynamic range is limited. In such cases, differences between fixed-gain and non-linear processing may be less noticeable, allowing EQ-based approaches to seem sufficient to overcome the effects of hearing loss during demonstrations. But in real-world conditions audio signals span much wider dynamic ranges:
- Speech signals can span up to ~70 dB
- Music typically ranges between 40–60 dB
The more dynamic the signal, the more it exposes the limitations of fixed-gain systems.
To deliver consistent audibility and comfort across the full range, personalization must adapt in real time.
The appropriate solution class: non-linear dynamic range compression
To address the level-dependent nature of hearing loss, sound processing must also operate in a level-dependent way. This is the role of non-linear dynamic range compression.
Unlike EQ, non-linear processing dynamically adjusts gain depending on input level:
- Low-level signals receive more gain → restoring audibility
- High-level signals receive less gain → preserving comfort
This approach mirrors the natural compressive behavior of the healthy cochlea.
Wide Dynamic Range Compression (WDRC): the clinical standard
The most widely used implementation of this principle is Wide Dynamic Range Compression (WDRC), a non-linear processing technique that adjusts gain based on input level to restore audibility and maintain listening comfort.
Developed specifically to compensate for loudness recruitment, WDRC:
- restores access to low-level sounds
- maintains comfort at higher intensities
- approximates natural loudness perception
Research shows that non-linear compression:
- improves speech intelligibility
- enhances listening comfort
- reduces listening effort
As a result, it has become the dominant processing paradigm in modern hearing aids.
![[lightbox]](https://cdn.prod.website-files.com/6818bfbe7d79e080f9ab7199/69e62270b7584b8ea8a66afa_wide-dynamic-range-compression-wdrc-vs-eq.png)
Bringing auditory science into consumer audio with Mimi Sound Personalization
Mimi Sound Personalization operates within this non-linear solution class, enabling perceptually accurate hearing compensation that linear EQ-based approaches cannot achieve.
Unlike a standard wide dynamic range compressor in a hearing aid, the unique design of Mimi's sound processing is modeled after the physiology and behaviour of the complex circuits in the human hearing system.
Mimi’s technology combines:
- Fast-acting feed-forward compression
- Delayed feedback attenuation control (DFAC)
- A subsequent linear gain stage
Together, these elements simulate how the cochlea and early auditory pathways process sound in real time.
![[lightbox]](https://cdn.prod.website-files.com/6818bfbe7d79e080f9ab7199/69e6229e7f17873552f81420_mimi-hearing-processing-vs-natural-hearing-diagram.png)
From signal processing to perceptual accuracy
This biologically inspired approach enables accurate reconstruction of perceived loudness across signal levels. In practice, this means:
- Low-level details become audible without over-amplifying louder sounds
- Dynamic contrasts are preserved
- Audible artifacts and distortions are minimised
- Listening remains comfortable across any content
Unlike a conventional EQ, which reshapes frequency balance, Mimi’s processing restores the relationship between sound intensity and individual perception.
How processing approaches shape the listening experience
The differences between processing approaches become most apparent when applied to real-world audio signals.
In a healthy auditory system, the full signal is perceived as rich, balanced, and detailed.
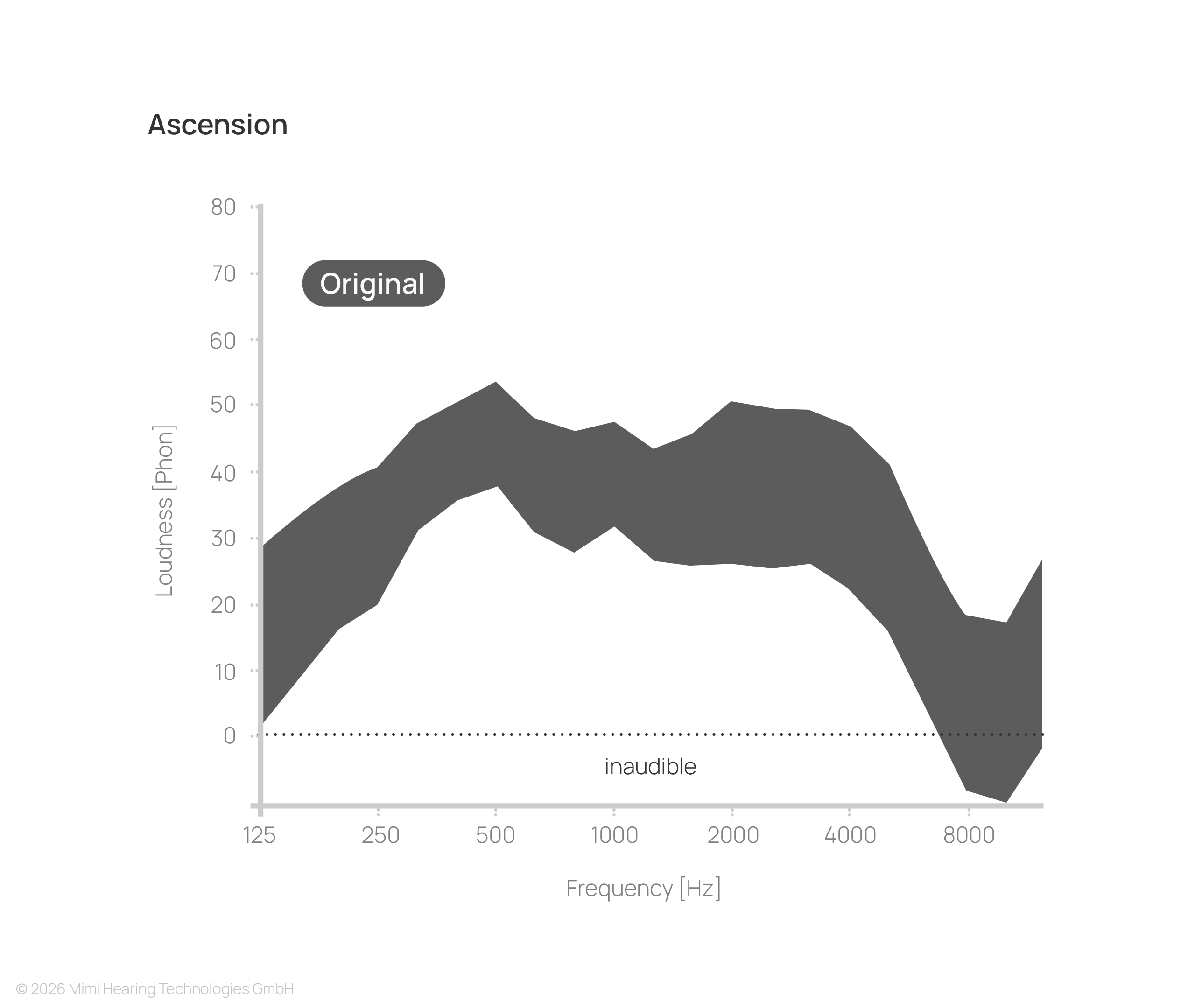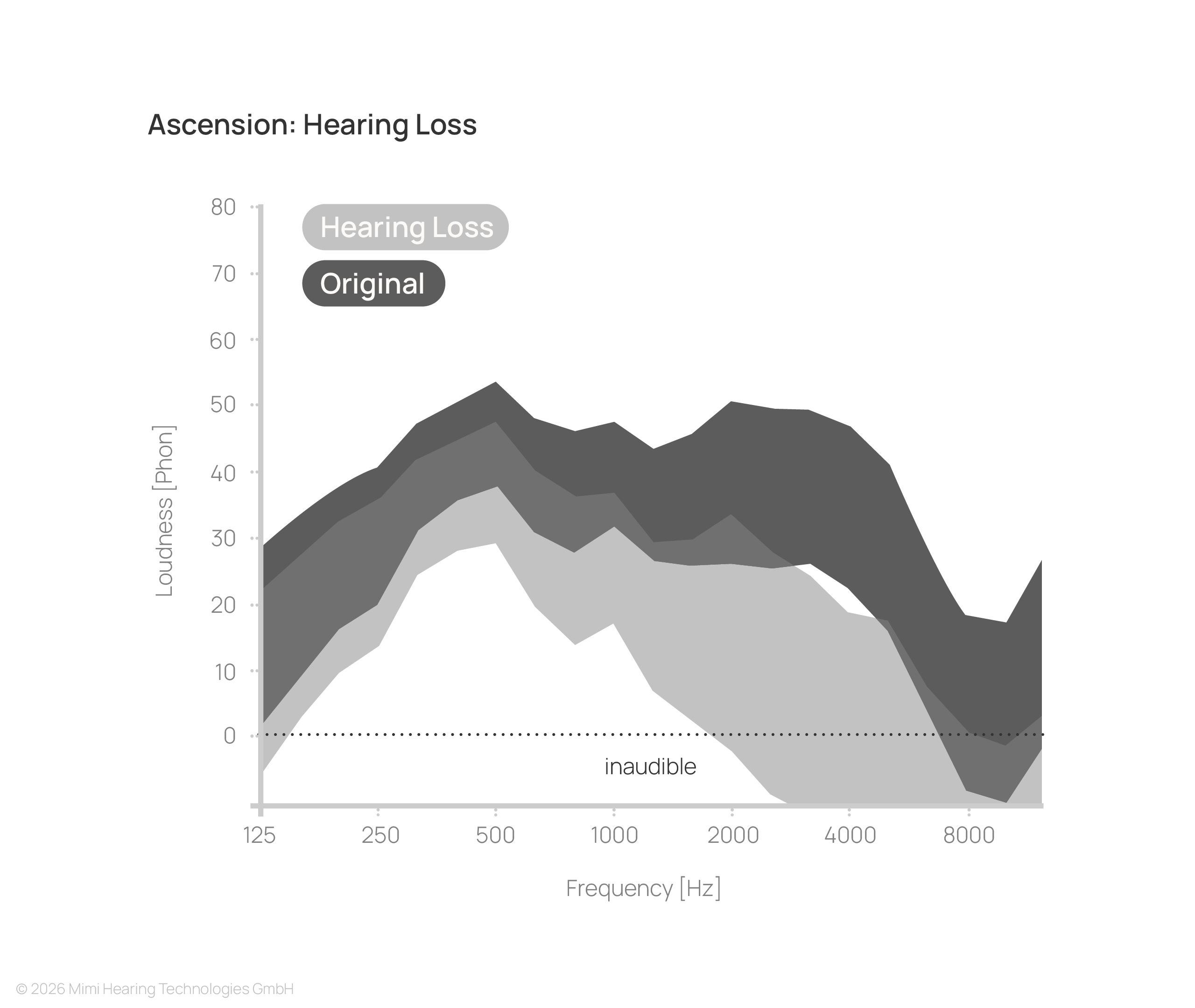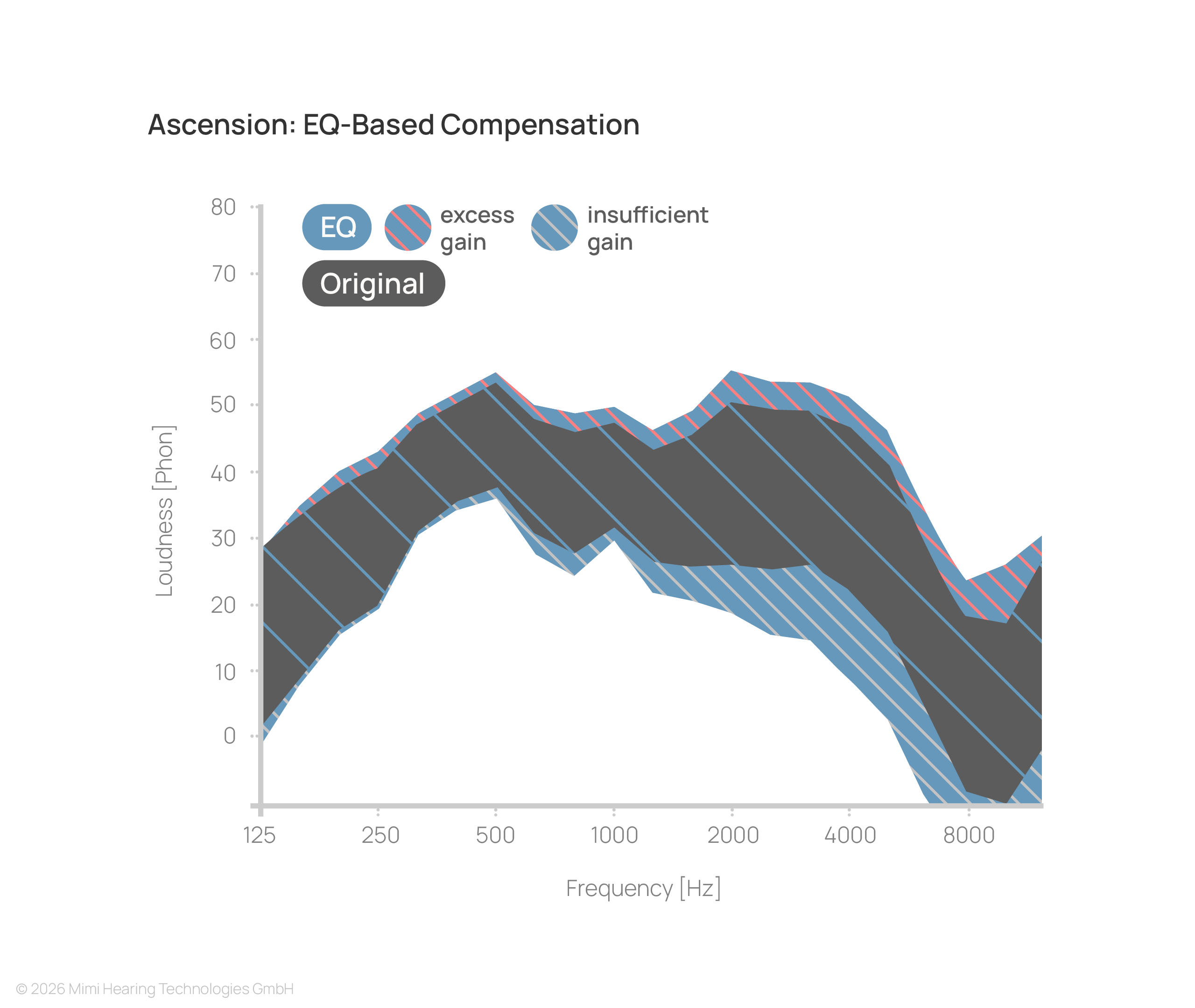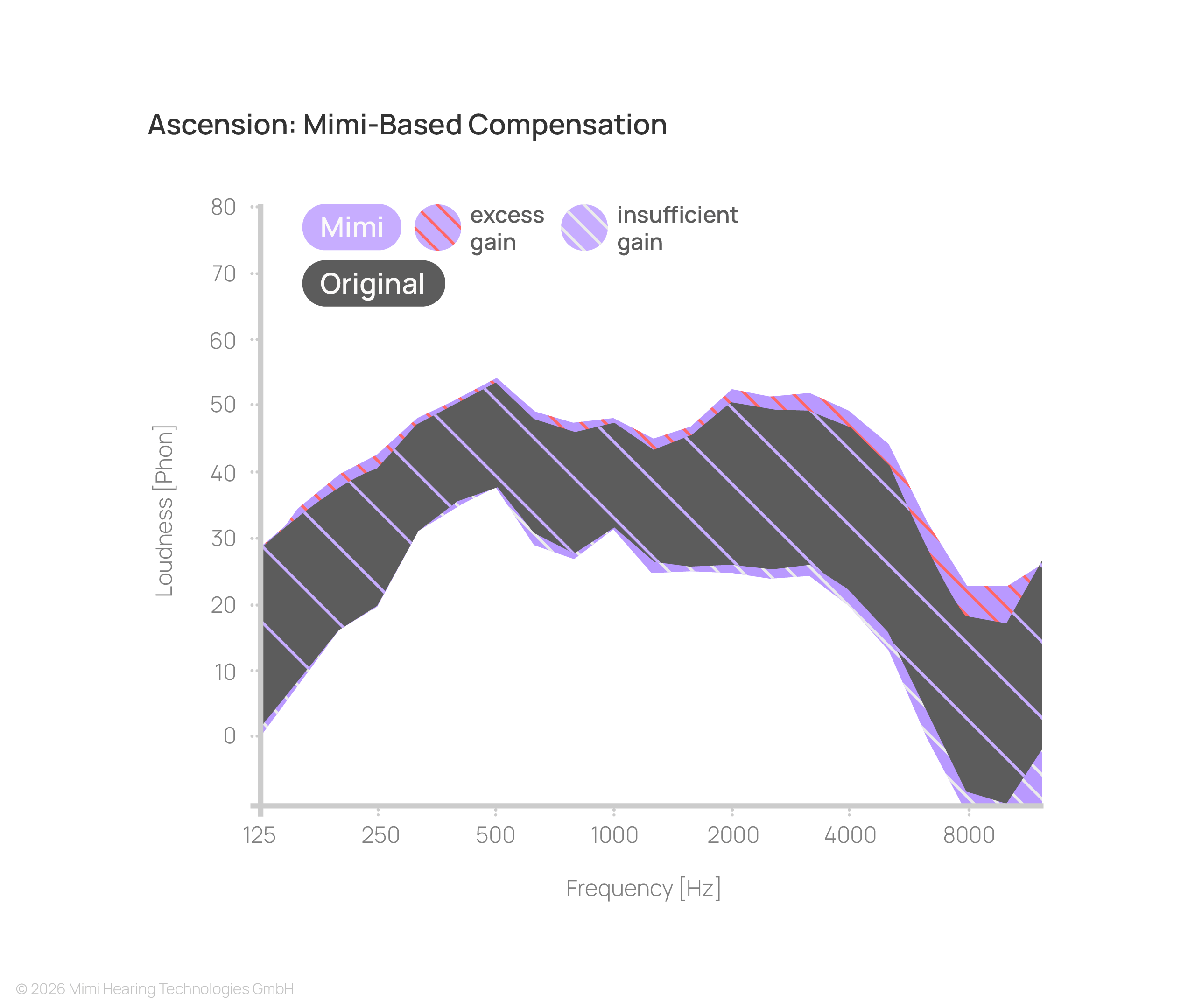
With hearing loss, substantial parts of the signal fall below the threshold of audibility, resulting in a reduced and less detailed listening experience.
How the restoration of this lost information is handled depends entirely on the processing approach. This becomes particularly evident in content with wide dynamic range:
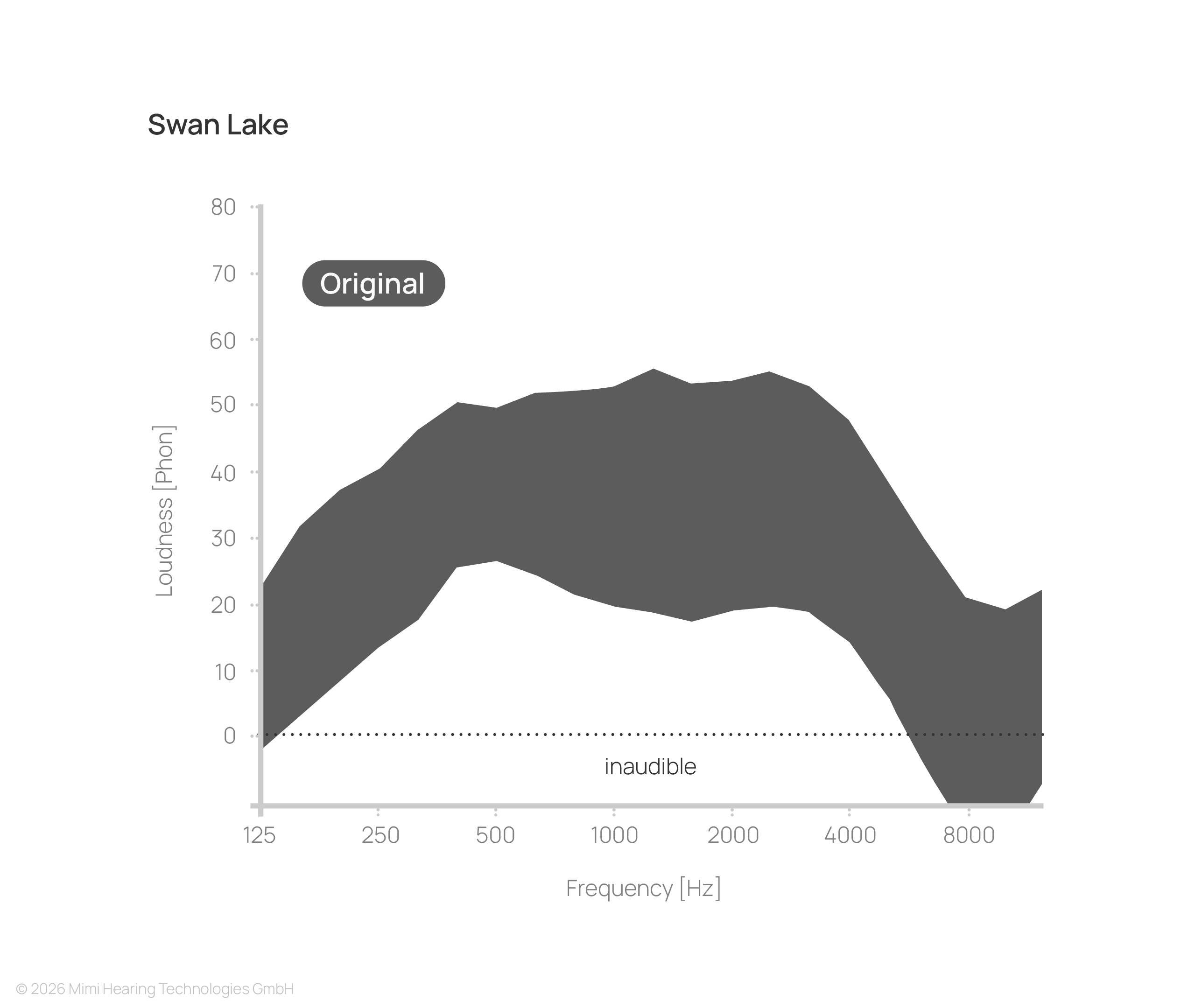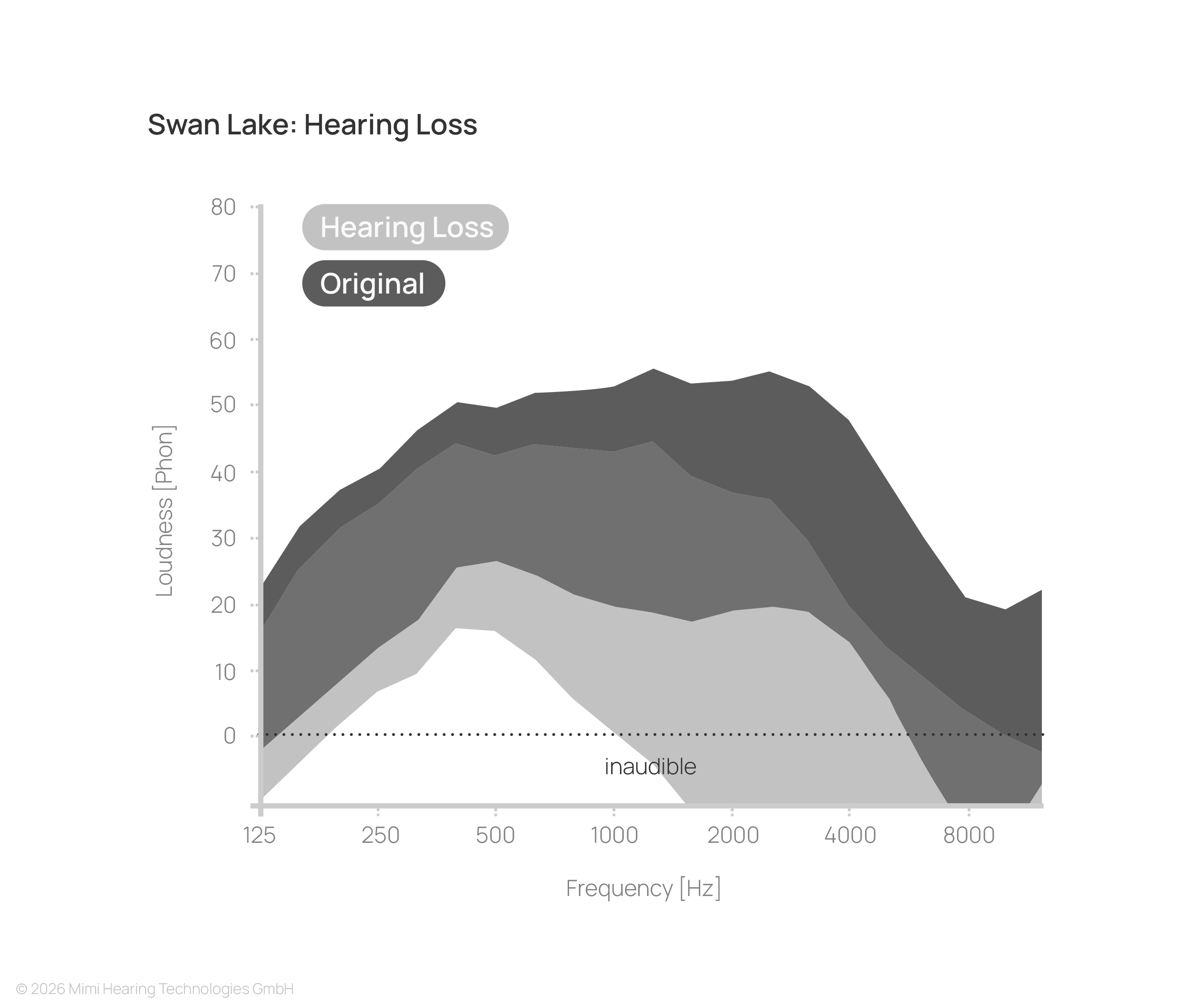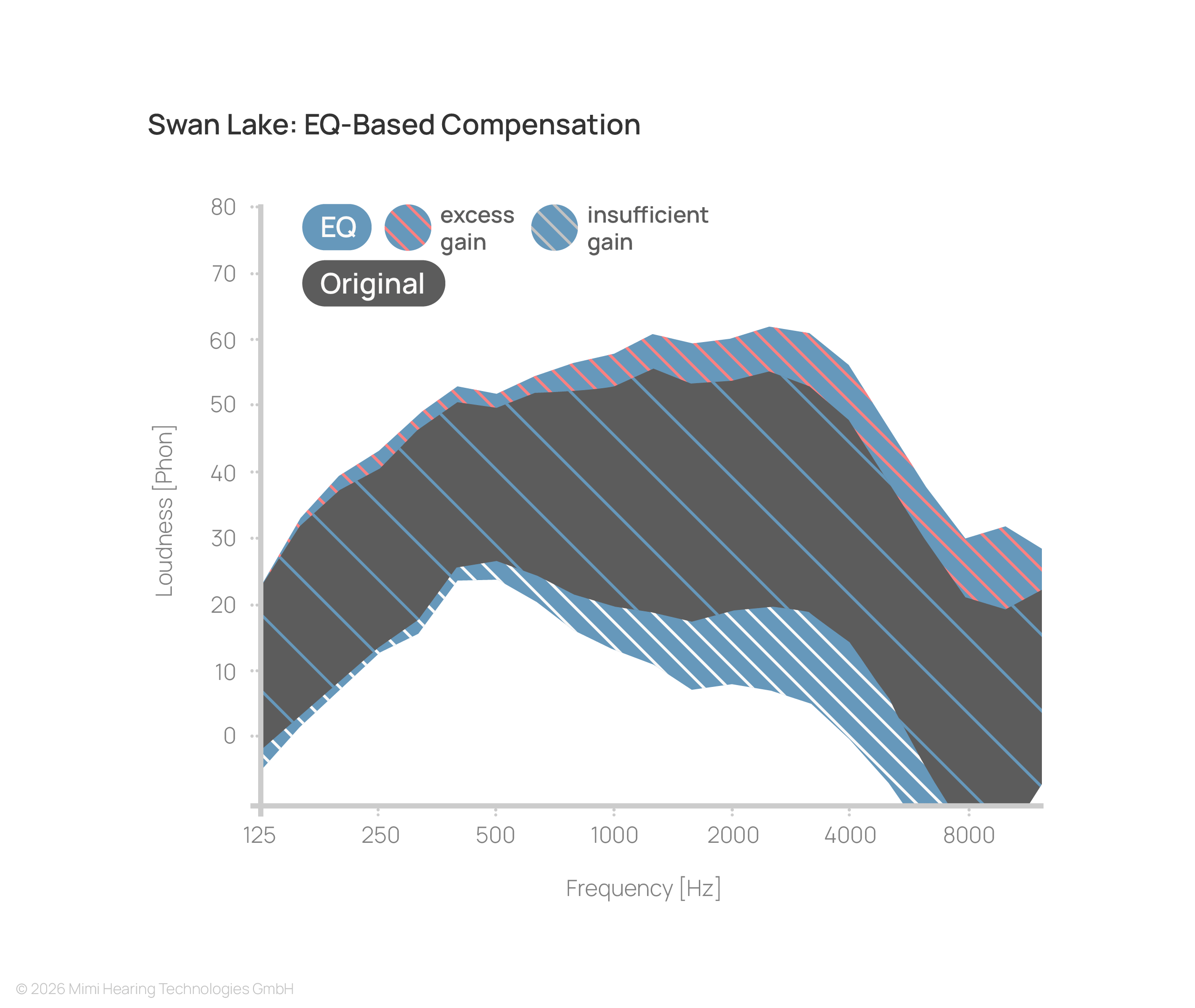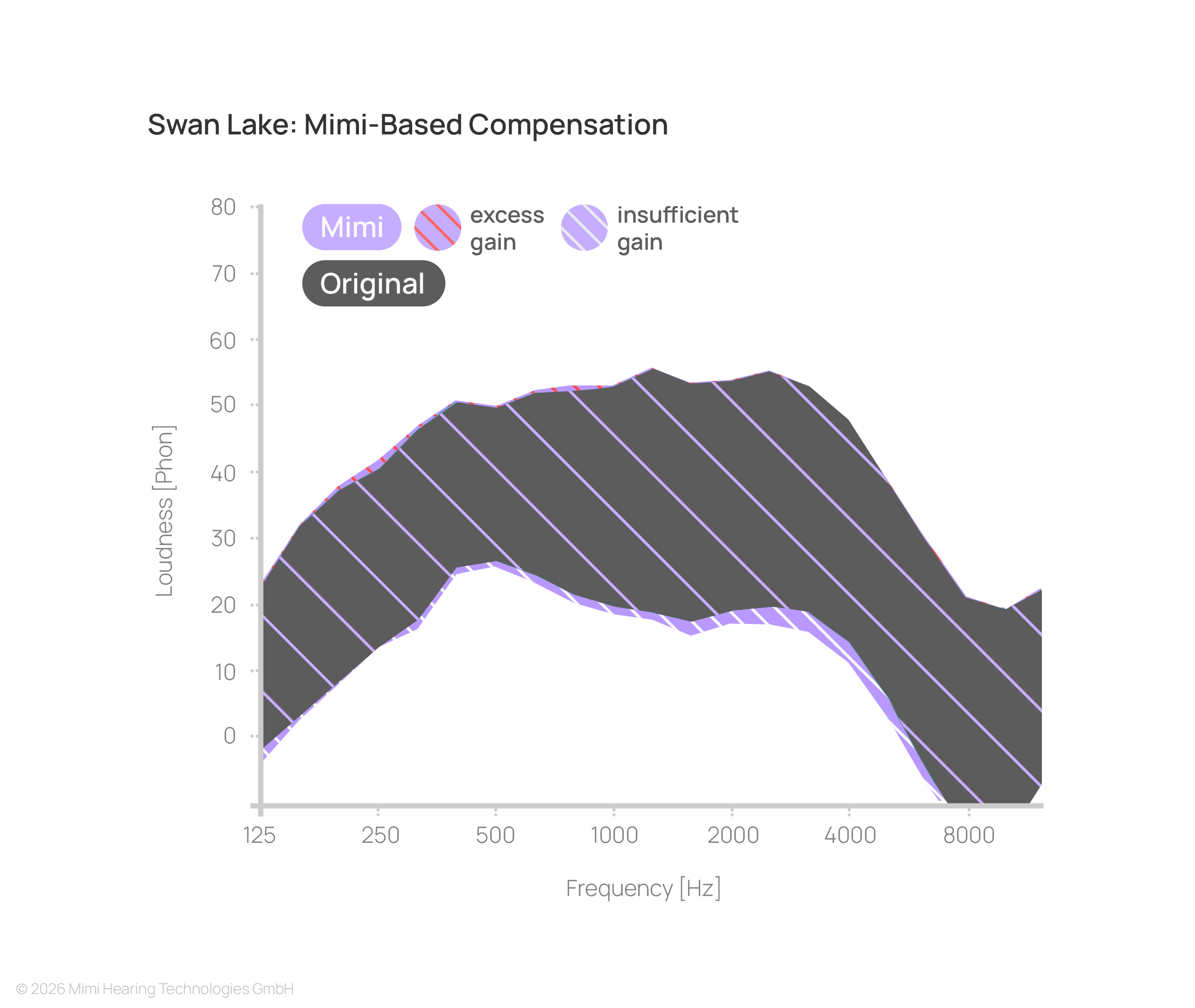
While linear EQ-based processing takes into account the individual frequency-dependence of the hearing loss, it disregards signal level. Consequently, even when optimally tuned, faint parts of the signal remain below their original perceived loudness, while higher-intensity components are excessively amplified.
This results in an unbalanced experience, where important details are lost and louder elements become uncomfortable.
The same limitation appears across different types of content, such as a modern instrumental track:
Non-linear processing approaches avoid this imbalance by adapting gain depending on both frequency and signal level.
This enables low-level details to become audible while maintaining comfort for louder components, restoring a more balanced and complete listening experience.
A structural, not incremental, difference
The distinction between Mimi Sound Personalization and standard EQ-based solutions is structural, not incremental.
Equalization is fundamentally a tone-shaping tool. It applies variable gain across frequency bands, but treats all signal levels equally. While useful for adjusting spectral balance, it cannot restore the altered loudness perception associated with cochlear hearing loss.
The strategic decision is therefore not between two forms of EQ, but between linear tone adjustment and non-linear loudness restoration.
Mimi Sound Personalization therefore should not be viewed as an alternative EQ implementation, but as a different class of sound processing altogether.
What this means for product teams
As consumer audio devices increasingly integrate hearing-related features, expectations are evolving. Users are no longer looking for just “better sound.” They expect sound that adapts to how they hear. This requires moving beyond static frequency-based adjustments towards perceptually accurate, hearing-aware personal sound.
Hearing-aware sound personalization refers to audio processing that adapts to an individual’s hearing profile and perceptual characteristics, rather than applying fixed signal adjustments.
For companies building next-generation audio products, the choice of processing strategy directly impacts:
- Accurate sound perception
- Listening comfort
- Speech intelligibility
- User satisfaction
- Product differentiation
As hearing health becomes a more prominent topic, these factors will increasingly define competitive advantage.
Conclusion: beyond EQ
Hearing-aware sound personalization is not about refining EQ. It requires adopting processing models aligned with human auditory science. Wide dynamic range compression is not merely a feature enhancement, it is a foundational capability for delivering consistent audibility and comfort across real-world listening conditions.
Mimi Sound Personalization represents this shift: from static sound tuning to accurate, perception-based audio processing.
Frequently asked questions
Why is EQ not sufficient for hearing loss compensation?
EQ applies fixed gain regardless of input level, which leads to under-amplification of soft sounds and over-amplification of louder sounds.
What is non-linear audio processing?
Non-linear audio processing adjusts gain dynamically based on signal level, enabling more accurate representation of sound for listeners with hearing loss.
What makes Mimi different from EQ?
Mimi Sound Personalization uses biologically inspired, level-dependent processing to restore perceptual balance, rather than applying static frequency-based adjustments.
Find out more
For product teams looking to move beyond EQ-based approaches:
👉 Learn how Mimi enables hearing-aware audio experiences with Mimi Sound Personalization.
👉 Download the white paper "Beyond EQ: Why hearing-aware Sound Personalization requires non-linear processing" to go deeper into the science with a more detailed exploration of the auditory science, technical frameworks, and real-world implications: